Sun Microsystems' Java programming language seems to have strayed far from its origin in 1991 as a language for networking consumer gadgets, such as a set-top for interactive television. It's tempting to frame the story as a rags-to-riches tale of a tiny language that far surpassed the lowly aspirations that its creators, James Gosling and his colleagues, had for it. Instead of being embedded inside toasters, TVs, and ovens; it's now running on some of the most powerful servers on the Internet, serving information to millions of people around the world. But this really only proves how successful their design was for a programming language designed for networking all kinds of devices.
The tale turned especially interesting on May 23, 1995, when Sun officially announced that Java was being released and that support for it would be built into Netscape's dominant Navigator browser.
It's hard to imagine now the excitement that this created then. Web pages that had been static were suddenly electric—going online was transformed from a static, black and white landscape to a dynamic, colorful Oz.
The tale turned especially interesting on May 23, 1995, when Sun officially announced that Java was being released and that support for it would be built into Netscape's dominant Navigator browser.
It's hard to imagine now the excitement that this created then. Web pages that had been static were suddenly electric—going online was transformed from a static, black and white landscape to a dynamic, colorful Oz.
The San Jose Mercury News reported:
Many leading-edge designers today are buzzing about Sun Microsystems, Inc.'s new software that the Mountain View-based company hopes will turn the Web into a rocking new medium. The software enables producers to make the Web as lively as a CD-ROM, but with the added advantages of continuous updates and real-time interaction between people.
Java's platform independence made it possible to write and compile a client-side application that would run in any user's browser, regardless of whether their machine was a Unix box, a Macintosh, a Windows PC, or anything else supported by Netscape. These mostly tiny applications—applets—introduced scrolling text, sound, motion, and games that made browsing the Web a dynamic experience while strong security features preventing malicious actions by programs made it a more secure experience.
Java on the client side was one of the important forces that contributed to the Web's explosive growth over the next five years. It was this growth that set the stage for a new role for Java, on the server side.
The World Wide Web has grown from a virtual conference center for the academic community to a cosmopolitan bazaar of commerce, entertainment, and information exchange available to users of nearly every age, education level, and nationality. To develop and serve this new market, a diverse variety of applications have been and continue to be developed. And as it turns out, Java has matured into an excellent programming language for building these new applications and services, due to features such as network support, platform independence, and robustness, features that have been inherent in its core design from the beginning.
As the importance of Java as a server-side programming language has increased, Sun has dramatically expanded the number and types of features that support networking and distributed computing. According to Sun, the number of classes and interfaces in the Java standard edition has increased by an order of magnitude in a little over five years: from 212 in version 1.0 to 2,738 in version 1.4. Many of these new features are in packages supporting such things as security, networking, XML (Extensible Markup Language), RMI (Remote Method Invocation), naming services, and database connectivity.
Many leading-edge designers today are buzzing about Sun Microsystems, Inc.'s new software that the Mountain View-based company hopes will turn the Web into a rocking new medium. The software enables producers to make the Web as lively as a CD-ROM, but with the added advantages of continuous updates and real-time interaction between people.
Java's platform independence made it possible to write and compile a client-side application that would run in any user's browser, regardless of whether their machine was a Unix box, a Macintosh, a Windows PC, or anything else supported by Netscape. These mostly tiny applications—applets—introduced scrolling text, sound, motion, and games that made browsing the Web a dynamic experience while strong security features preventing malicious actions by programs made it a more secure experience.
Java on the client side was one of the important forces that contributed to the Web's explosive growth over the next five years. It was this growth that set the stage for a new role for Java, on the server side.
The World Wide Web has grown from a virtual conference center for the academic community to a cosmopolitan bazaar of commerce, entertainment, and information exchange available to users of nearly every age, education level, and nationality. To develop and serve this new market, a diverse variety of applications have been and continue to be developed. And as it turns out, Java has matured into an excellent programming language for building these new applications and services, due to features such as network support, platform independence, and robustness, features that have been inherent in its core design from the beginning.
As the importance of Java as a server-side programming language has increased, Sun has dramatically expanded the number and types of features that support networking and distributed computing. According to Sun, the number of classes and interfaces in the Java standard edition has increased by an order of magnitude in a little over five years: from 212 in version 1.0 to 2,738 in version 1.4. Many of these new features are in packages supporting such things as security, networking, XML (Extensible Markup Language), RMI (Remote Method Invocation), naming services, and database connectivity.
The Right Tool at the Right Time
The Java programming language got to where it is today not
simply by being in the right place at the right time, but by being the right
tool in the right place at the right time.
There's been a lot of research into object-oriented design
since the 1960s, and there are now quite a few object-oriented languages, but
before Java, no purely object-oriented language had come into widespread use for
general-purpose programming. Undeniably, C++ has achieved great popularity, but
because it is a hybrid language, it is all too easy to lapse into
non-object-oriented ways and to abuse the features it has inherited from C.
Java, for many people, has turned out to be a better C++. Java is C++ stripped
of the unsafe features that can lead to programming errors. After all, consumer
gadgets, such as VCRs and toasters, should not crash and require rebooting.
Java enforces object-oriented programming because it was
designed from the beginning as an object-oriented language. Though this is not a
book about object-oriented design or programming, the fact that Java is so
thoroughly object-oriented means that our approach must, by necessity, be
object-oriented, as well. It will especially affect the way we approach using a
database. In the end, to use Java effectively, we need to be true to its
object-oriented nature.
Networking is Fundamental
The key to the growth of the Internet and the Web is
networking. In the famous formula immortalized as Metcalf's Law, Robert Metcalf,
inventor of Ethernet and founder of 3Com, observed that a network increases in
proportion to the square of the number of participants. (Actually, the formula
is n2 – n, which approaches n2 for large numbers.) This is
because, as the number of participants increases, the number of possible links
and interactions between them increases geometrically. Synergy is obtained as
more people work together and interact with each other.
Tapping this new market/community/cyberspace and harnessing
that synergistic energy is an exciting challenge. Java and databases are
fundamental building blocks for building network-based applications that meet
this challenge.
Networks and Applications
Despite the hype, not all network applications are Web
applications. There are two principal types of applications designed to run on a
network: client-server and multitier (or n-tier) applications.
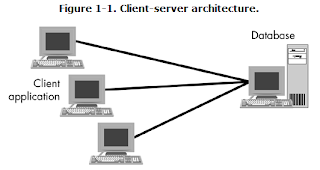
Client-server applications are the most traditional type.
Typically, client-server applications involve a database on the server and an
application running on the users' computers, where most of the processing takes
place (Figure 1-1). The main drawback of
this architecture is maintainability. When a new version of the application is
introduced, it must be distributed to many users at the same time, lest
incompatibilities between versions cause problems. Another drawback is that the
client machine must typically be fairly powerful, because most of the processing
takes place on the client machine.

Multitier applications introduce an intermediate layer, called
middleware, which, like the database, runs on a
server—possibly, but not necessarily, the same server as the database. In a
multitier application, much of the processing that ran on each user's machine is
moved into this middleware layer and is shared by all users. The user's machine
is typically responsible only for presenting the information to the user and
allowing the user to interact with the display and provide input


Organizations of all sizes use distributed applications, and
these applications can be built using either the client-server or the multitier
model. Some examples of these applications include:
-
Library reference database
-
Enterprise resource planning (ERP) systems
-
Customer Relationship Management (CRM) systems
-
Procurement systems
-
Document storage
A Web application is a specific
variety of multitier application. Where a more traditional architecture would
use a stand-alone application on the client machine, a Web application generates
HTML documents and interacts with a Web browser on the client, using the HTTP
protocol.
Some examples of the types of Web sites using this architecture
include:
-
Information, news sites
-
Catalog sales
-
Entertainment, gaming
-
Brokerages, auctions
All of these distributed applications have one important thing
in common: Except for possibly games, they all exist primarily to move and
process information. This information must be reliably stored and retrieved—it
must be persistent.
The Value of Persistence
Virtually all applications, not just network applications, need
some degree of persistence. The importance of persistence is easy to overlook at
first. Imagine a student writing a research paper, using a PC to format and
print it. Imagine that the PC was unable, for some reason, to save the file to
disk. The student would probably be wise to (at least) print out the paper once
in while, in case the electricity is shut off. Paper isn't usually the best way
to store information that is in a digital format but it's better than not
storing the information at all.
Similarly, when a user places an order from an online catalog
or a writer submits a story to a Web magazine, this information needs to be
stored somehow. The easiest way may be to keep these records in memory, but as
was the case with the poor student, this isn't very safe, because a system crash
or a power outage would permanently erase them. It would be better to write them
out to a file or a set of files in the operating system.
Consider a Web magazine. It may be sufficient simply to create
a file for each article. Perhaps there is a single editor or a webmaster
responsible for putting the article in the right place in the Web server's file
system and updating the appropriate Web pages to link in the new story.
Other types of Web sites have more complex needs. They need to
keep track of such things as user names, passwords, preferences, and orders.
Writing these bits of information out to files and managing them quickly becomes
a major development task. The issues involved are far from trivial.
Database management system vendors have already solved the
issues that arise from managing lots of information for lots of users: such
things as allowing concurrent access, combining information from different sets
of data on a record-by-record basis, providing different levels of access
according to user, and treating a set of changes as a single transaction to
ensure integrity of the data.
If a distributed application requires more than trivial
persistence, a database system is almost always the best solution.

Types of Databases
One of Java's chief strengths is that it enforces
object-oriented programming. To get a database to work effectively with Java, we
have to start with a database that supports objects or, if it doesn't, we must
somehow find a way to bridge that gap, translating between Java's objects and
whatever the database considers its basic unit of storage. This problem of
bridging the gap between object-oriented Java and non-object-oriented databases
is often called the mismatched impedance
problem.
Object Databases
Considering that such a thing exists, it might seem that the
easiest thing to do is to use a database that supports objects directly. That is
probably true. In fact, for a while, there was quite a bit of excitement and
optimism in the market and in the development community about object databases.
A few years ago, the future couldn't have looked brighter for object databases.
Unfortunately, for a number of reasons, they have since largely failed in the
market except in certain niches, such as embedded databases and multimedia
applications.
The main problem with object databases is that they do one
thing really well—provide persistence for objects. It is relatively easy to
build an object-oriented system using an object database. Unfortunately, the
overall performance is not very good; in particular, they are slow in performing
ad hoc queries. There is also some question about their ability to scale—that
is, the ability to handle large amounts of data and transactions, which is a
requirement for large distributed systems, such as popular Web sites.
Object-Relational Databases
Object-relational database are relational databases with
object-oriented features added. Among the main characteristics are that the
tables can store user-defined datatypes, such as objects; that tables or objects
can be nested; and that methods can be associated with the objects in the
tables.
Oracle has had object-relational features in its database since
release 8. We will explore these features in depth in Chapter 6, "Oracle Object-Relational
Features" and its use with Java in Chapter 9, "Advanced JDBC Features." In
summary, although it does allow us to model our data as objects within the
database, it is still difficult to integrate with a program written in Java. In
particular, mapping between Oracle database objects and Java objects is
complicated. Oracle database objects support methods, but this is of
questionable value, because they are not easily mapped to the Java objects
either; this may lead to having similar code in two places, which is certainly
not desirable.
Despite these concerns, however, Oracle's object-relational
features are useful for developing objects and methods that need to be shared by
different applications, especially if those applications are written in
different languages.
Relational Databases
Relational database management systems (RDBMSs) are the most
popular type of database in the market today. E.F. Codd at IBM established much
of the theory behind relational databases in the 1970s. There is an absolute set
of criteria that defines a relational database, but because no database product
at this writing totally meets it, the following informal description is probably
more useful:
-
Data consists of records stored in tables as rows.
-
Each record includes a fixed set of fields, with each field corresponding to the columns of the table.
-
One column must be a primary key—a required and unique value—so each record can be exclusively located.
-
Views—alternate ways of looking at a table or a set of tables—must include support for inserting, updating, and deleting the appropriate data in the underlying table or tables.
-
The database must support null—an unknown value not equivalent to zero or a blank.
-
A high-level relational language—not necessarily, but usually Structured Query Language (SQL)—must be provided to support data definition, data manipulation, and database administration.
-
Data constraints must be enforced by the database and cannot be bypassed.
RDBMSs are the standard today for a number of simple reasons:
They are well studied and well understood. They scale well. Companies such as
Oracle have invested extraordinary amounts of time and money in developing
versatile, flexible, and powerful products. RDBMSs are so well established that
we really need to change the question from, "What is the best way to provide
persistence in an object-oriented system?" to "What is the best way to use a
relational database to provide persistence for an object-oriented system?" That
is, given that relational databases are the industry standard (and for good
reasons), what is the best way to bridge the impedance mismatch?
One way to bridge the gap between an object-oriented system and
a relational database is to use a mapping layer. "Object
Relational Mapping and Java Data Objects.) Because this layer creates a degree
of independence between the database and the rest of the system, it can protect
each from the effects of changes in the other. This can improve the
maintainability and reusability of the system, both key goals of object-oriented
design.
Oracle and Java
There are numerous good reasons to choose Oracle over its
competitors in the RDBMS market. These include, in no particular order:
-
Oracle has the best support for Java and has had that support for the longest time—though other vendors, particularly IBM and Sybase, are moving quickly to catch up.
-
With regard to the market share, Oracle is the market leader. However, as of 2002, IBM is not far behind. Although Oracle is far and away the leader on Unix, IBM makes up the difference to a large extent in the mainframe market.
-
Of the top three databases—IBM DB2 and Microsoft SQL Server being the other two—Oracle is the most platform-independent.
These are good reasons for choosing Oracle over its
competitors. But to an extent, it doesn't really matter because this is also a
book about Java database programming, and the mantra of Java programmers is:
"Write once, run anywhere."
Portability is one of the biggest selling points for Java. In a
perfect world, it wouldn't make any difference which database we used, as long
as it has support for Java. But there are imperfections in the current database
world.
-
Java support is not complete in any database—not even Oracle.
-
Even where two databases implement a particular Java feature or technology, they are not always fully compatible.
-
Relational databases do not implement relational standards in compatible ways.
-
Sometimes we need to rely on a relational database's proprietary features.
To the extent possible, this book will stick to platform- and
database-independent code and techniques. It will clearly be identified where
this is not possible. Recommendations will be provided where it is appropriate.
It should not be difficult to carry over what you learn here to other
databases.
Overview of Oracle's Java Features
There are many ways that we can use Java together with
Oracle:
-
Use Java and SQLJ (with embedded SQL statements) outside the database.
-
Use Java and Java database connectivity (JDBC) outside the database.
-
Use Java inside the database as stored procedures.
-
Use a middleware layer to manage the connection between Java and the database.
-
Use a mapping layer to provide more-or-less transparent persistence for Java—transparent meaning that Java does not need to manage persistence explicitly.
As we will see, these are not mutually exclusive options.
SQLJ
SQLJ is the easiest way to perform database access from Java.
It is an ANSI standard way of embedding static SQL statements in Java code. A
precompiler is used to translate the SQLJ + Java code into a pure Java source
file. In the case of Oracle's SQLJ implementation, at least, the underlying
connectivity is actually achieved with JDBC, and it is possible to mix SQLJ code
with JDBC.
JDBC: Java Database Connectivity
The fundamental technology linking Java and databases is Java
database connectivity (JDBC; Figure 1-3).
The JDBC specification defines a way to access any form of tabular data from
Java—from text files to spreadsheets to databases. Java provides a set of
interfaces in the core language, the java.sql package. The database vendor
typically provides an actual implementation in the form of a JDBC driver. After
loading the driver in our code, we can connect to the database, send SQL
statements to the database, and retrieve results.

Java Stored Procedures
Java methods can be loaded and run in the database in three
different ways:
-
Procedures can be called from interfaces such as SQLJ or JDBC, or interactively from SQL*Plus, using the CALL statement. Procedures can optionally have input and output parameters.
-
Triggers are set up to run automatically when data is inserted, deleted, or updated. These are typically used to maintain a dependent column, write to a log, or enforce complicated constraints.
-
Functions are similar to procedures but are required to return a single value. They can be used just like built-in SQL functions in SQL statements, such as SELECT, DELETE, INSERT, and UPDATE.
Procedures, triggers, and functions differ in the way they are
loaded, published, and called, but they are more alike than different. They are
all included in the term stored procedure.
There are numerous advantages to running a program on the
database server, rather than on the client machines. If a program is
data-intensive, running it on the server will significantly reduce the amount of
data traffic over the network. This will benefit the client, but it may also
benefit other users, too, even though additional processing takes place on the
shared server. A procedure can be set up to provide limited access to data.
Stored procedures were traditionally written in Oracle's native
procedural language, PL/SQL. (Actually, PL/SQL is still worth considering for
use in stored procedures where performance is more important than portability.)
We'll encounter a bit of this legacy later, when we find that we must publish
the interface of our Java method as a mapping to PL/SQL.
J2EE, Application Servers, and JDO
In addition to using a database for persistence, networked Java
applications often need additional or enhanced services, such as messaging,
naming and directory services, Web services, connection pooling, and transaction
services.
J2EE and Application Servers
In its J2EE specification (Java 2, Enterprise Edition), Sun
defines a specific set of these features, including a technology, EJB
(Enterprise JavaBeans), that can manage persistence automatically for
applications. A product that implements J2EE services is called an application
server. The most popular application servers are BEA WebLogic and IBM WebSphere
but Oracle also has one that is largely compatible with the others and easy to
use.
In order for a product to claim J2EE compliance, it must be
able to provide the full set of J2EE functionality specified by Sun. But the
single compelling use that many people find for an application server is as an
EJB container. Because the container can manage persistence automatically, the
developers of the application can largely or entirely avoid SQL and many of the
details of database programming.
Java Data Objects
In addition to J2EE, Sun has published a specification for Java
Data Objects (JDO)—an API for Java persistence. JDO provides a framework for
mapping Java objects to a database of any kind and, therefore, isn't an
object-relational API, per se. But naturally, implementations for relational
databases, by definition, provide object-relational mapping. JDO provides nearly
perfect transparent persistence. At the time of this writing—just six months
since the release of the specification—there are at least nine commercial
implementations already available and several open source projects underway.
No comments:
Post a Comment